隨著人們對健康管理的日益重視,家用電子血壓計已成為許多家庭的必備健康監(jiān)測工具。九安醫(yī)療作為知名的醫(yī)療器械品牌,其推出的KN520全自動上臂式電子血壓計,憑借精準(zhǔn)的測量、便捷的操作和人性化的設(shè)計,贏得了眾多用戶的青睞。
一、產(chǎn)品外觀與設(shè)計
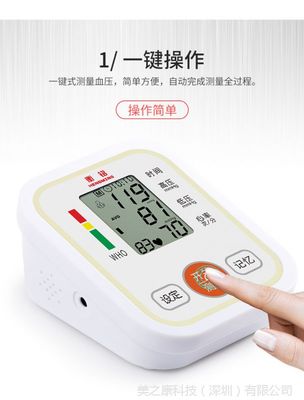
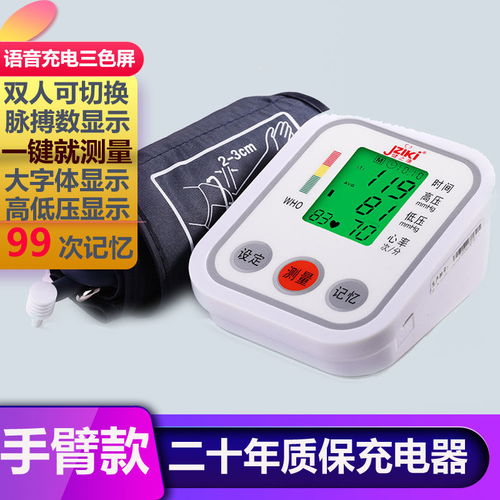
從產(chǎn)品圖片來看,九安KN520血壓計采用了簡潔大方的設(shè)計風(fēng)格。主機(jī)通常以白色或淺灰色為主色調(diào),搭配清晰的黑色液晶顯示屏,給人一種專業(yè)、潔凈的視覺感受。顯示屏尺寸適中,數(shù)字顯示大而清晰,即使視力不佳的老年人也能輕松讀取測量結(jié)果。
臂帶部分為標(biāo)準(zhǔn)的軟質(zhì)布料,內(nèi)置高靈敏度傳感器,并配有魔術(shù)貼,適合不同粗細(xì)的上臂周徑(通常范圍為22-32厘米)。設(shè)備整體設(shè)計緊湊,便于收納和攜帶,無論是放在家中固定使用,還是外出旅行時隨身攜帶,都非常方便。
二、核心功能與測量原理
KN520作為一款全自動上臂式血壓計,其核心優(yōu)勢在于操作的簡便性和測量的準(zhǔn)確性。
- 一鍵操作,全自動測量:用戶只需正確佩戴好臂帶,按下啟動鍵,設(shè)備便會自動加壓至合適壓力,然后緩慢放氣,全程自動完成收縮壓、舒張壓和心率的測量。整個過程無需手動聽診或判斷,極大地降低了使用門檻。
- 精準(zhǔn)測量技術(shù):它采用示波法原理,通過檢測袖帶內(nèi)壓力的波動來計算出血壓值。九安在血壓測量領(lǐng)域擁有成熟的技術(shù)積累,KN520通常內(nèi)置了智能加壓和模糊算法,能有效減少測量誤差,提供可靠的參考數(shù)據(jù)。
- 清晰顯示與提示:測量結(jié)果會清晰地顯示在屏幕上,包括高壓(收縮壓)、低壓(舒張壓)和脈搏值。許多型號還具備血壓水平指示燈(如通過顏色分區(qū)提示正常、偏高范圍)和心律不齊提示功能,讓用戶對自身狀況有更直觀的了解。
三、家用場景的優(yōu)勢
對于家庭用戶而言,九安KN520展現(xiàn)出了多方面的優(yōu)勢:
- 易于使用:簡單的操作步驟使得家庭成員,尤其是老年人,都能輕松掌握,實現(xiàn)日常自我監(jiān)測。
- 數(shù)據(jù)管理:部分型號可能支持多次測量值的記憶存儲功能,方便用戶追蹤一段時期內(nèi)的血壓變化趨勢,為健康管理或就醫(yī)提供數(shù)據(jù)支持。
- 舒適體驗:智能加壓技術(shù)可以快速判斷所需的壓力值,避免過度加壓帶來的不適感。
- 經(jīng)濟(jì)實用:作為國產(chǎn)品牌的主力型號之一,KN520在保證質(zhì)量的前提下,通常具有較高的性價比,是家庭購置的理想選擇。
四、使用注意事項
為了確保測量結(jié)果的準(zhǔn)確性,使用時需注意:
- 測量前應(yīng)靜坐休息5-10分鐘,避免運動、進(jìn)食、吸煙或飲用咖啡因飲料。
- 臂帶佩戴位置要正確,氣囊中心應(yīng)對準(zhǔn)上臂肱動脈,袖帶下緣距肘窩約2-3厘米,松緊以能插入一根手指為宜。
- 測量時保持身體坐正,手臂平放于桌面,與心臟處于同一高度,保持安靜不要說話。
- 建議在每天同一時間段、相同身體狀態(tài)下進(jìn)行測量,以獲得可比較的數(shù)據(jù)。
###
總而言之,九安KN520全自動上臂式電子血壓計是一款設(shè)計人性化、操作簡便、測量可靠的家用健康監(jiān)測產(chǎn)品。其清晰的產(chǎn)品圖片所展示的,不僅僅是一個儀器,更是一份隨時守護(hù)家人心血管健康的安心保障。定期、規(guī)范地使用家用血壓計進(jìn)行監(jiān)測,是預(yù)防和管理高血壓及相關(guān)疾病的重要第一步。